Much has been written about the Modern Data Stack recently. Oftentimes, the focus is centered on the innovations around the movement, transformation, and governance of data. But when it comes to the analytics layer, articles end at the traditional endpoints where data is consumed, whether it be through dashboards, SQL query, or the building of data science models. The truth is that data-driven organizations should not be content with the same old approaches to data consumption. After all, tectonic shifts in technology usually revolutionize the experience for end-users in profound ways.
For example, technological shifts such as the Internet didn’t just improve the quality of phone calls and improve the resolution of your TV picture, but enabled complete shifts in digital social interactions and put every song and movie in everyone’s hands. The same re-imagination of user experiences should come for consumers of data and analytics, and we’ll break down how we get there.
In This Post
What is the Modern Data Stack?
A Modern Data Stack is a suite of tools used for gathering, storing, transforming, and analyzing data. Each of these layers play a key role in your organization’s goals to get better insights from vast amounts of data and to proactively uncover new opportunities for growth. Unlike legacy technologies, you can usually get started very quickly, enjoy a pay-as-you-go pricing model, and won’t be locked in with a specific vendor for the entire stack, so mix and matching best-of-breed tools for your Modern Data Stack is a core tenant.
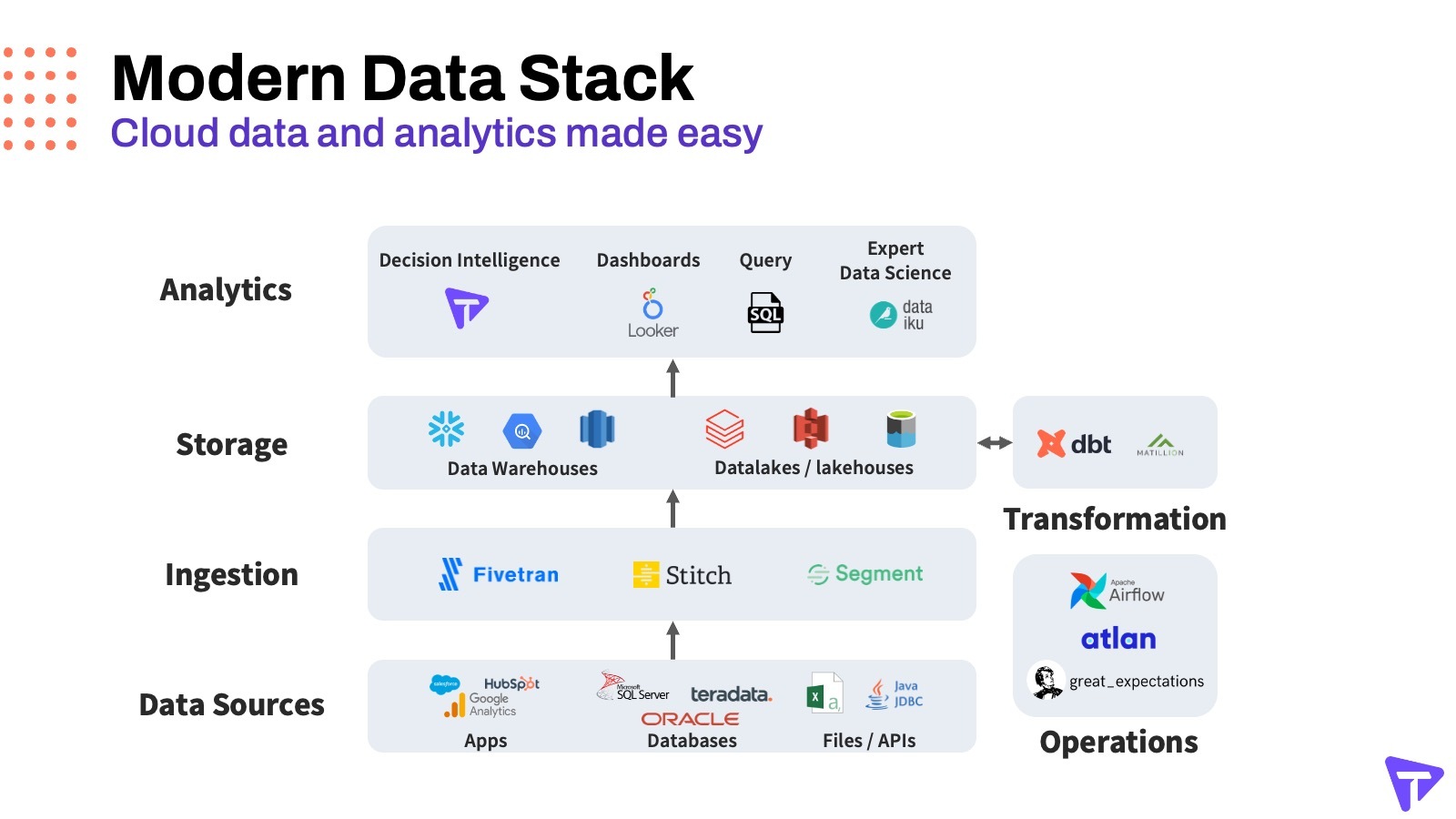
Think of the MDS as a well-layered trifle dessert for data:
- The bottom layer is your data sources, such as applications like Salesforce and Google Analytics, databases such as Oracle and SQL Server, and files such as spreadsheets or XML.
- The ingestion layer extracts data from the various data sources with automated pipelines, using tools such as Fivetran, Stitch, or Segment, allowing your team to work with the freshest data possible
- The storage layer includes cloud data warehouses such as Snowflake and Amazon Redshift, and data lakes such as Databricks and Amazon S3.
- The transformation layer cleans up raw data in order to facilitate subsequent analysis. Example tools are DBT (Data Build Tools), which is a SQL command-line program that allows data analysts and engineers to transform data. Another is Matillion, a data integration and transformation solution purpose-built for the cloud and cloud data warehouses.
- The operations layer includes tools such as Apache Airflow which is an open-source workflow management platform for data engineering pipelines, as well as Atlan, which connects to your storage layer to assist your data teams to democratize both internal and external data, while automating repetitive tasks.
- The icing on top is the analytics layer. This layer includes dashboard tools such as Looker, as well as SQL query, machine learning modeling tools such as Dataiku, plus a new form of augmented analytics that we call decision intelligence.
When it comes to the analytics layer, the typical tools people usually think about are dashboards for business users monitoring KPIs, SQL query for analysts to dig deeper, and ML modeling for expert data scientists. These techniques have been with us for decades and reinforce the traditional analytics process where businesses wait on data teams to work through their backlog in order to answer the important, and often times, new business questions. If organizations are going to take a fresh, modern approach to their data stack, they should also update the analytics experience for their users as well. At Tinace, we call this new approach Decision Intelligence, or Augmented Analytics 3.0, which combines business intelligence with AI and machine learning to get faster insights from their modern data stack. Let’s dive deeper into the four essential pieces for modernizing the analytics layer of the Modern Data Stack.
Automated Generation of Insights
With so much data and compute available in the cloud, it should go without saying that all that power should be utilized by automation to simplify and speed analysis and make it easier for technical and non-technical people to get answers from all the data. While manual querying of data will always be an essential tool for analyst teams, automated generation of insights empowers more people with an easier way to obtain important findings and in a much faster way.
Automation solves a problem that many organizations who do not even think they have “big data” actually have. Consider a dataset of just twenty columns or variables. In order to analyze up to four variables at a time in order to find the combinations that are correlated to a target metric, there are more than 6,000 combinations that you would have to visualize or evaluate. A specific example would be for an ecommerce brand to discover that sneakers sales spiked up for a specific brand, in a group of zip codes, in a given color, and for a specific customer age group. Having this type of insight may lead to new targeted campaigns or follow-up actions that would never be possible without understanding deep, granular patterns and relationships in the data.
With an automated process, it becomes easier to analyze all possible combinations of data instead of forming individual hypotheses and testing them by creating SQL query after SQL query to look across the data. In addition, you would be able to discover unknown “unknowns” you may not have thought of otherwise. Then, the system would be able to proactively push insights to you that you’re most interested in because it learns what data and metrics are important to you and your business. This augmentation represents the future of how analysts will get answers easier, iterate on insights discovery much faster, and even involve business users in the process and take organizations beyond dashboards.
Natural Language
As someone who knows how to code, but do not consider myself a programmer, I know there is a time and place for applying code in analyzing data. But I much rather prefer the modern experience of a search interface where I can ask questions to get the information I need, instead of needing to query in SQL or Python. That’s where natural language plays a part in the modern analytics layer. With a search interface that supports natural language, users can ask questions, like you would if you were speaking to one of your smart home devices, to get answers and visualize data that not only helps you understand what is happening in the business, but also identify the reasons why metrics change, and how to improve business performance through granular recommendations found in data.
Towards the goal of making data accessible to more people, natural language also plays a part in the narratives and data stories that are presented alongside data visualizations in an insight that is automatically generated. These narratives describe the specific findings of interest, as to help the user quickly understand the insight without having to interpret the visualization alone.
Machine Learning for Non Data Scientists
Applying Machine Learning to business data has become a popular path to advanced and predictive analytics for many organizations in recent years. But these capabilities should not just be the playground for PhDs and technical experts. Modern analytics is about upskilling more people in the data ecosystem. To that end, modern analytics is empowering a new generation of business analysts and data analysts with the superpowers of data science. Not only is this about making building ML models easier with point-and-click automated machine learning, but augmenting the process in a few key ways: making model outputs more explainable and transparent by making the process more visual and exploratory; automating the feature engineering to simply data prep (data prep is often cited by data scientists as the most time-consuming part about working with business data); and integrating models with an easy way for business users to visualize and interact with insights and predictions to strengthen the collaborative and iterative advanced analytics process.
Leverage Data Warehouse / Data Lake for Analytics
The last piece of the puzzle for the analytics layer that sits on top of the modern data stack is for the analytics layer to leverage the compute power of the storage layer. Proponents of the modern data stack usually prefer that data is not moved to the analytics layer and that all processing takes place in the data warehouse or the data lake (or lakehouse). In this model, the analytics layer acts as the interface for analytics users (whether they are business users, analysts, or data scientists) and any queries or machine learning jobs are pushed down to the storage layer for compute. The response is returned to the analytics layer for users to consume, interpret, and act on. A modern analytics layer such as Tinace gives organizations the flexibility to live query a data warehouse, perform live advanced analytics and machine learning with a data lake, as well as the capability to ingest data for internal processing when the situation calls for it.
Summary
In closing, the Modern Data Stack is a great innovation with a bright future, but the benefits shouldn’t just be about the underlying data plumbing. Organizations should also examine how the modern data stack can offer a new experience that takes insight-driven organizations to the next level, making it easier to make critical decisions faster and with more confidence than ever before.
To learn more about the Modern Data Stack check out our recent webinars “3 Must-Haves of a Modern Data Stack” and “Accelerating Insights & Analysis from a Modern Data Stack.”