What's New
Release 4.0
Release 3.9
Release 3.8
Release 3.7
Release 3.6
Release 3.5
Release 3.4
Release 3.3
Release 3.2
Release 3.1
Release 3.0
Release 2.4.1
Release 2.4
Free Cloud Trial
Release 2.3
Release 2.2
Release 2.1
Release 2.0
Release 1.8
Release 1.7
Release 1.6
Release 1.5
Tinace Home
Search (Natural Language)
Search in Tinace
Guide Me
How to Search
Business View List / Columns
Query
Search Result
Discover Insights
Interactions
Chart Operations
Add to Vizpad
Table View
Switch Chart type
Change Chart Config
Apply Filters
Change Formatting
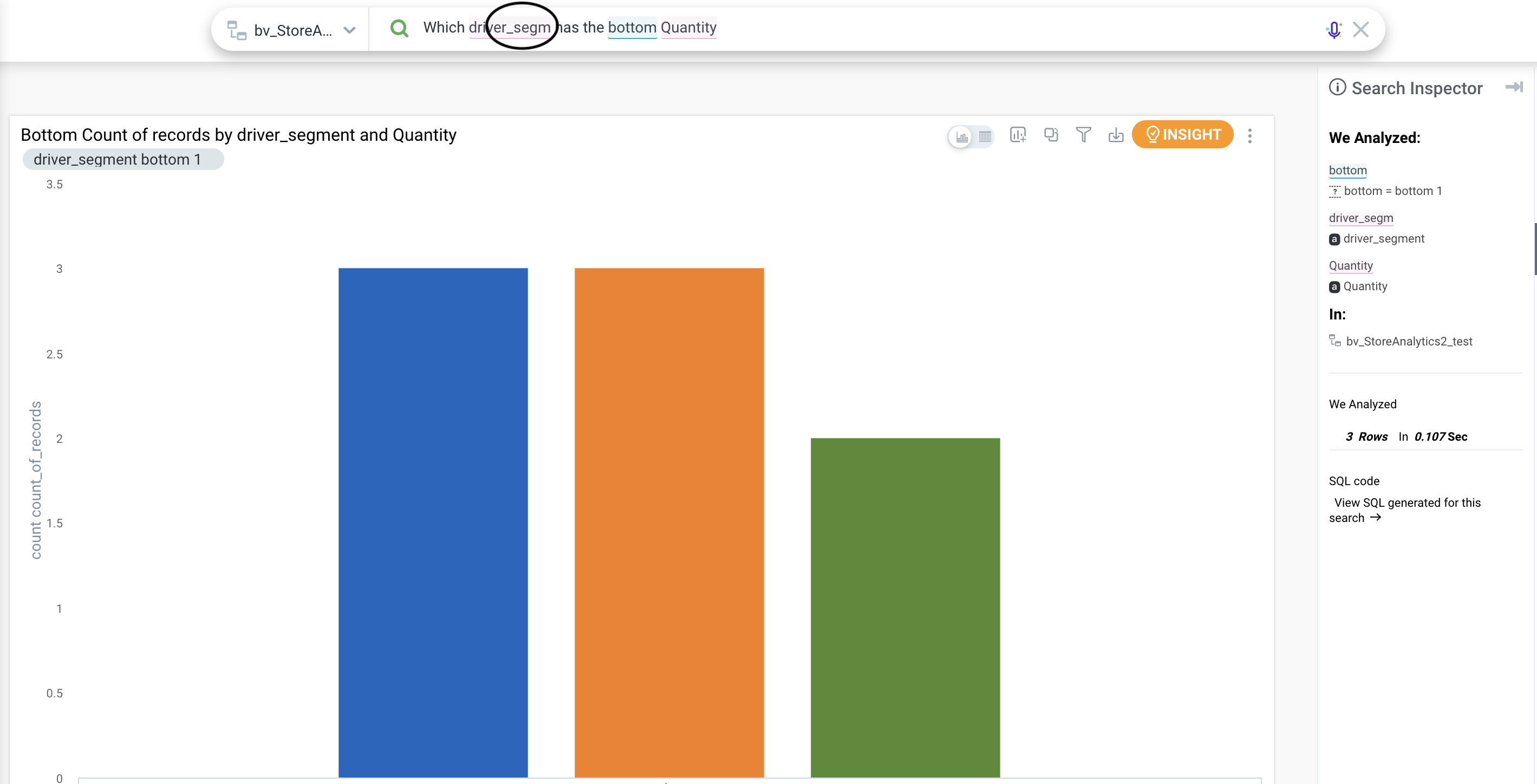
Measure Aggregation - Market Share Change
View Raw Data
Download/ Export
Embed URL
Partial Data for Visualization
Best-fit visual
Add to Vizpad
Adding the chart to a Vizpad
Customize the auto-picked columns
Search Query Inspector
Teach Tinace
History
Guided Search
Add Guided Search Experience
Display Names in the Search Guide
Guided Search
Guided Search Syntax and Attributes
Deep Dive
Search Synonyms
Maps in Search
Search Keywords
Percentage Queries
Time Period Queries
Year-over-Year Analysis
Additional Filters
Pagination
List View In Search Results
Embed Search
Personalized Search
Search Cheat Sheet
Filters in Help Tinace Learn
Explore (Vizpads)
Dashboards in Tinace
Vizpad Creation
Create Interactive Content
Create Visualization Charts
List of Charts
Common Chart Types
Line Chart
Bar Chart
Pie Chart
Year-over-Year Functionality in Vizpad
Area Chart
Combo Chart
Treemaps
Bubble Chart
Histogram
Heat-Map Charts
Scatter Chart
Other Charts
Cohort Chart
For each chart
Create Visualization Charts
Global Filters
Embedded Filters
Other Content
Creating Interactive Content
Vizpad level Interactions
Viz level Interactions
Discover Insights
Drivers
Discover hidden insights - Genius Insights
How Genius Insights works
Discoveries in Insight
Anomalies on Trend
Interactions
Chart Operations
Embedding Vizpad
Vizpad Consumption
Collection of Interactive Content
Vizpad level Interactions
Global Filter on the fly
Global Resolutions
Refresh
Notifications / Alerts
Share
Download / Export
Unique name for Vizpads
Edit Column Width
Viz level Interactions
Multi-Business View Vizpads
Embedding Viz & Vizpads
Discover (Genius Insights)
Discoveries
What are discoveries
Type of Discoveries in Tinace
Create Discoveries
Kick-off Key Drivers
Edit Insights
Key Driver Insights
Components of Key Drivers
What are Key Drivers
Edit Key Driver Insights
Segment Drivers
Trend Drivers
Trend Insights (Why Insights)
Comparison Insights
Components of Comparison Insights
Create Comparison Insight
What are Comparison Insights
Edit Comparison Insights
Others Actions
Save
Refresh
Share Insights
Download
Adding Insights to Vizpad
Insights Enhancements
Embedding Insight
Impact Calculation for Top Contributors
Marketshare
Live Insights
Predict (Machine Learning)
Machine Learning
AutoML
How to create AutoML models
Leaderboard
Prediction
Others
What is AutoML
Point-n-Click Predict
Feed (Track Metrics)
Assistant (Conversations)
Tinace on Mobile devices
Data (Connect, Transform, Model)
Connectors
Connector Setup
Edit Connector
Live Connect
Data Import
Cache
Direct Business View
JDBC connector for PrestoDB
Google BigQuery Connector
Snowflake
List of Connectors by Type
Tables Connections
Custom SQL
Schedule Connector Refresh
Share Connections
Datasets
Load Datasets
Configure Datasets (Measure/Dimensions)
Transform Datasets
Create Business View
Share Datasets
Copy Datasets
Delete Datasets
Data Prep
Datasets
Data Profiling / Statistics
Transformations
Dataset Transform
Aggregate Transforms
Calculated Columns
SQL Transform
Python Transform
Create Hierarchies
Filter Data
SQL Code Snippets
Multiple Datasets Scripting SQL
Column Transforms
Column Metadata
Column type
Feature type
Aggregation
Data type
Special Types
Synonym
Rename Column
Filter Column
Delete Column
Variable Display Names
Other Functions
Dataset Information
Dataset Preview
Alter Pipeline Stage
Edit / Publish Datasets
Data Pipeline (Visual)
Alerts
Partitioning for JDBC Datasets
Export Dataset
Data Fusion
Schedule Refresh
Business Views
Create Business View
Create Business View
Datasets Preview & List
Add datasets to Model
Joins
Column selection
Column configuration
Primary Date
Geo-tagging state/country/city
Save to Fast Query Engine
Publish
Business View
What is Data Model
BV Visual Representation (Preview)
BV Data Sample
Learnings (from Teach Me)
Custom Calculations (Report-level Calc)
Predictions on BV
BV Refresh
Export/ Download Business View
Share Business View
URL in Business View
Request Edit Access
Projects (Organize Content)
Monitor Tinace
Embed Tinace
Settings
About Tinace
User Profile
Admin Settings
Manage Users
Team (Users)
Details & Role
Create a new user
Edit user details
Assigning the user data to another user
Restricting the dataset for a user
Deleting a user
Assign User Objects
Teammates (Groups)
Authentication & Authorization
Application & Advanced Settings
Data
Machine Learning
Genius Insights
Usage tracking & Support
CDN
Download Business View, Dataset, and Insights for Live BV
Customize Help
Impersonate
Data Size Estimation and Calculation
Effective Sharing Permissions
Change Week Start Day
Dataflow Access
Enable In-memory operations on Live sources
Language Support
Administration
Setup & Configuration
Installation Guide
Kubernetes Setup
Tinace Architecture
Deployment Architecture
System Requirements
Installation Overview
On-Prem Deployment Instruction Set
AWS Marketplace
Autoscaling
Backup and Restore
Help & Support
Help and Support System
Guided Tours
Product Videos
Articles & Docs
FAQ
Provide Feedback
Connect with Tinace team
Support Process
Notifications
Getting Started Videos
Getting Started
Tinace Connect
Tinace Data Overview Video
Connecting to Flat Files Video
Connecting to Data Sources Video
Live Connections Video
Data Refresh and Scheduling Video
Tinace Prep
Getting Started with Tinace Prep Video
Transformations, Indicators, Signatures, Aggregations and Filters Video
SQL and Python Video
Working with Dates Video
Data Fusion Video
Business View Video
Business Mapping Video
Report Level Calculations Video
Writeback to DB
Natural Language Search
Getting Started with Search Video
How-To Search Video
Customizing Search Results Video
Search Interactions Video
Help Tinace Learn
Explore - Vizpads
Getting Started with Vizpads Video
Creating Vizpads Video
Creating and Configuring Visualizations Video
Viz-Level Interactions Video
Vizpad-Level Interactions Video
Auto Insights
Getting Started with Auto Insights Video
Discovery Insights Video
Segment Insights Video
Trend Insights Video
Comparison Insights Video
Iterate on Insights Video
Tinace Feed Video
Predict - ML Modeling
Getting Started with Predict Video
AutoML Configuration Video
AutoML Leaderboard Video
Point-n-Click Regression Video
Point-n-Click Classification Video
Point-n-Click Clustering Video
Point-n-Click Time Series Video
Point-n-Click PythonML Video
Explainable AI Video
PredictAPI Video
Apply ML Model Video
ML Refresh and Schedule Video
Admin
Best Practices & FAQs
- All Categories
- What's New
- Release 3.7
Release 3.7
 Updated
by Ajay Khanna
Updated
by Ajay Khanna
We are thrilled to announce our newest release, 3.7. This release is full of several key enhancements to improve user's experience and ability. Read more below!
Admin
Usage Data Model BV Built
Operating a scalable Augmented BI platform for large number of users in the enterprise requires understanding how resources are consumed and how the users are engaging with the functionality in the application. In order to help administrators and users understand their usage, Tinace is introducing new Usage Business Views (UBVs). The UBVs offer transactional details across both the infrastructure and application usage.
UBVs comprise of the Usage Statistics, Job Statistics and Infrastructure Metrics business views. These BVs get updated continuously with information on the types of objects and datasets the users interacts with most, the jobs that get submitted on the infrastructure metrics consumed by the instances of Tinace. The BVs can be used in a flexible manner to perform search as well as build bespoke vizpads, with the views and KPIs of choice for the purposed of the admins. For a detailed description of the UBVs and what they track, please see the Usage Business Views article.
Support to add role to user group
The roles for users will be adjusted based on the highest role assigned to them within a group. This becomes the user's "effective" role.
Scenario: Suppose a User has ExplorerRole and Admin add the user to AdminRole user group. In this case, user’s access will be updated to the Admin role from ExplorerRole. If the admin removes the user from the AdminRole group, Users access is returned back to ExplorerRole (i.e. previous role of user) or ViewRole if not defined by admin or no previous role existed.
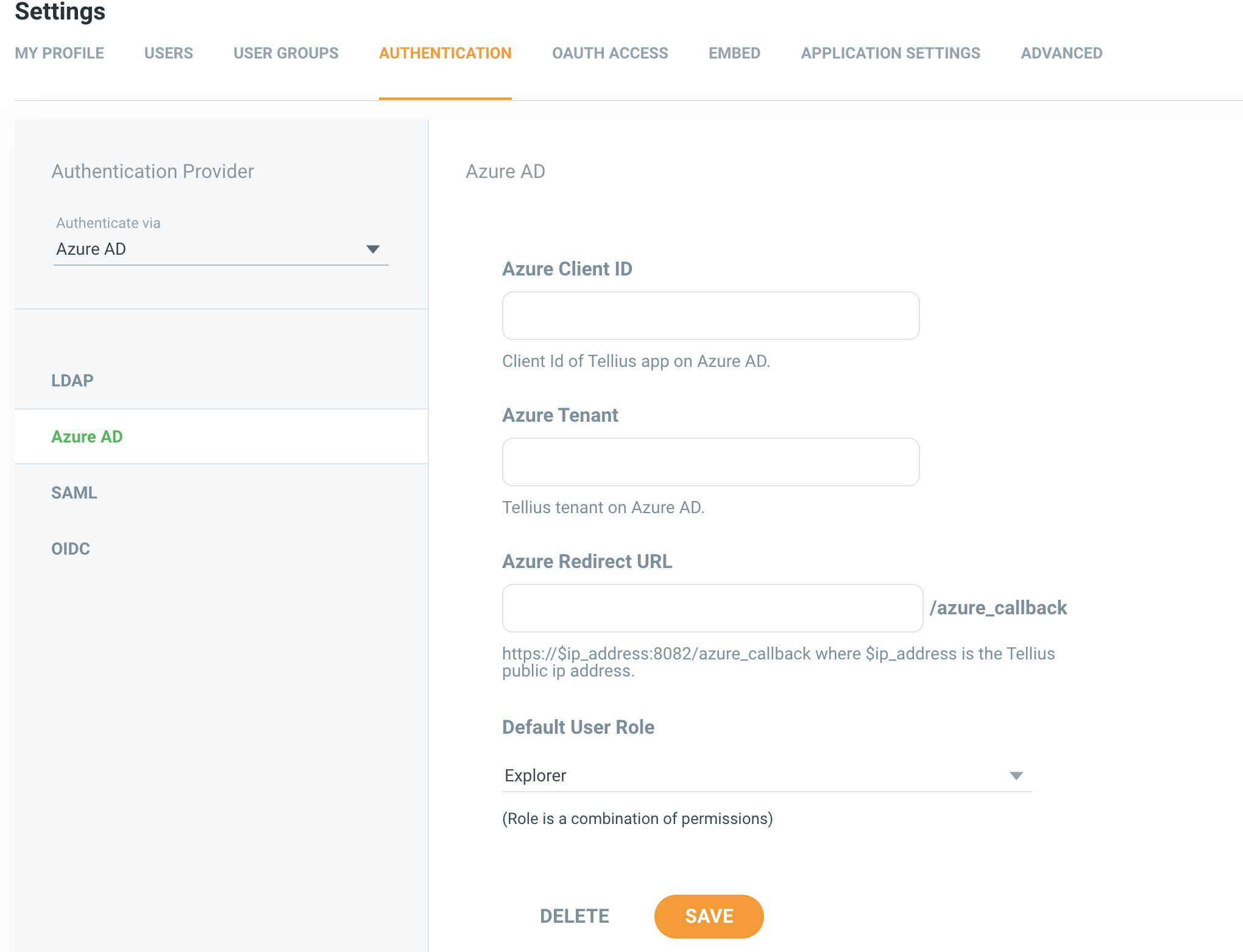
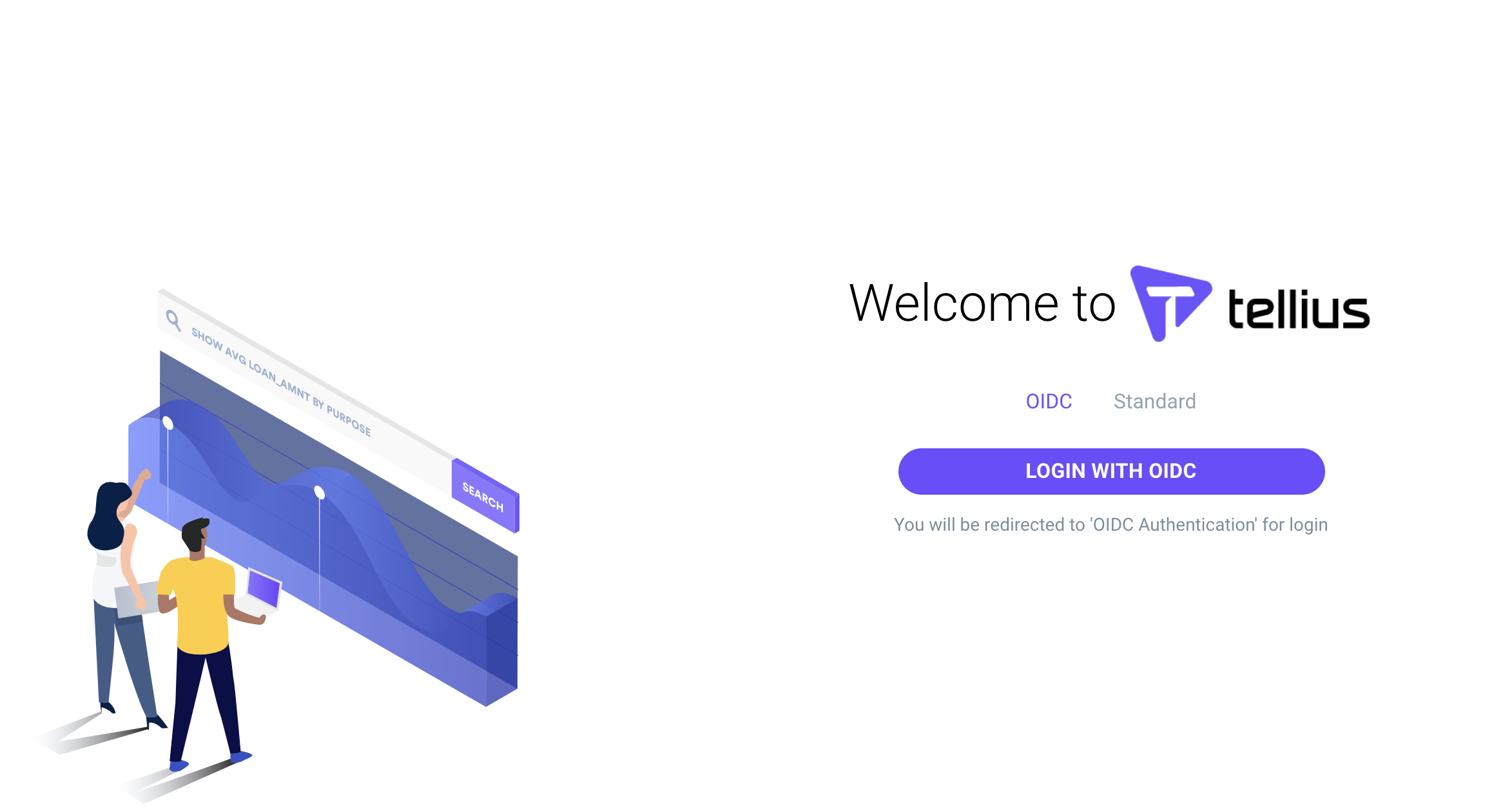
SSO Improvements
In Tinace 3.7, admins can enables SSO methods including LDAP, OIDC or Azure AD. When SSO using LDAP or Azure AD is enabled, by default the users will get a message at login to use the respective credential instead of a Tinace credential. The users can still opt to use the Tinace native login with the Tinace credentials, even if other SSO options are enabled by default.
Settings Menu:
Login screen:
Mobile App Updates: Search and Feeds
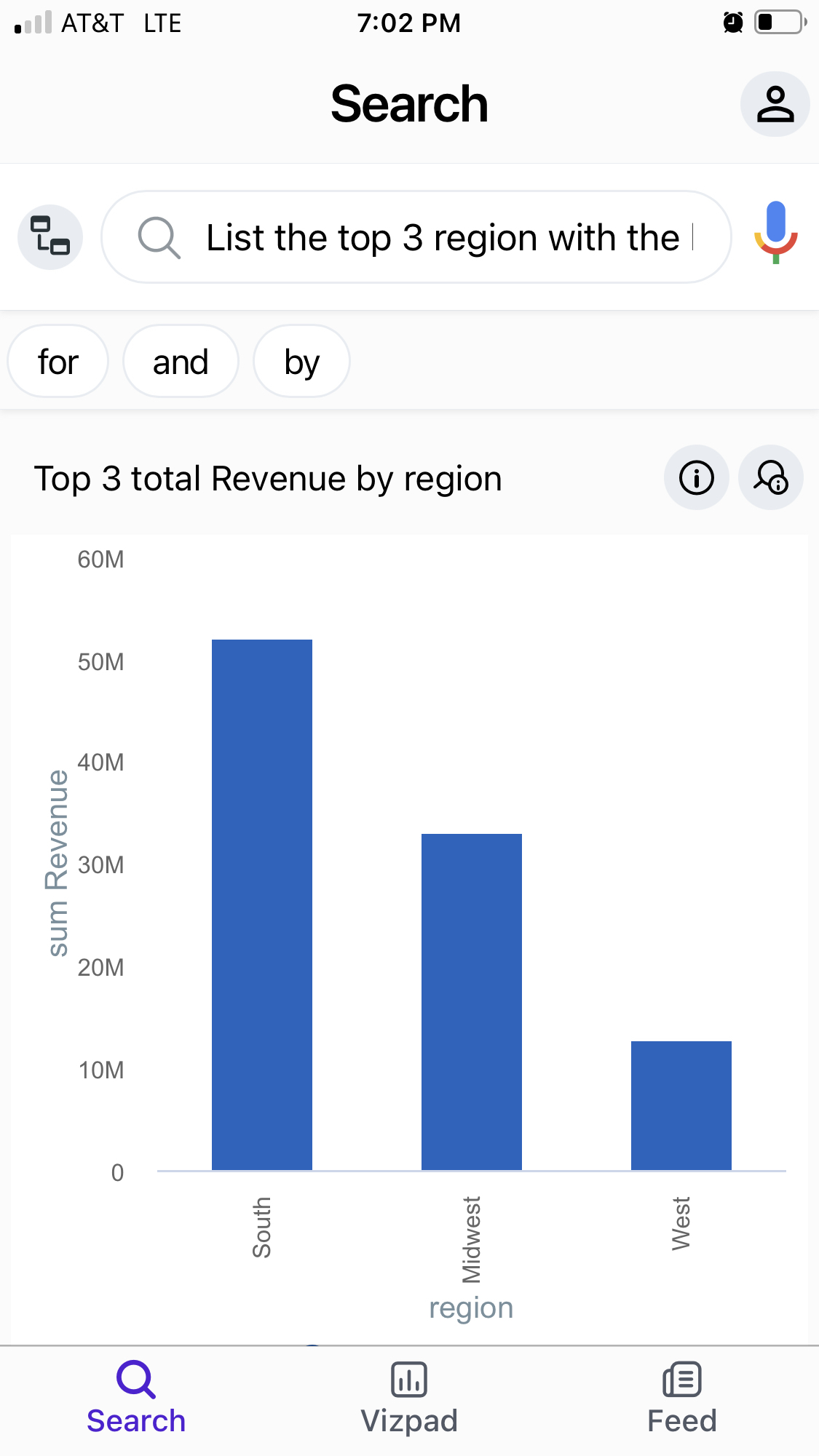
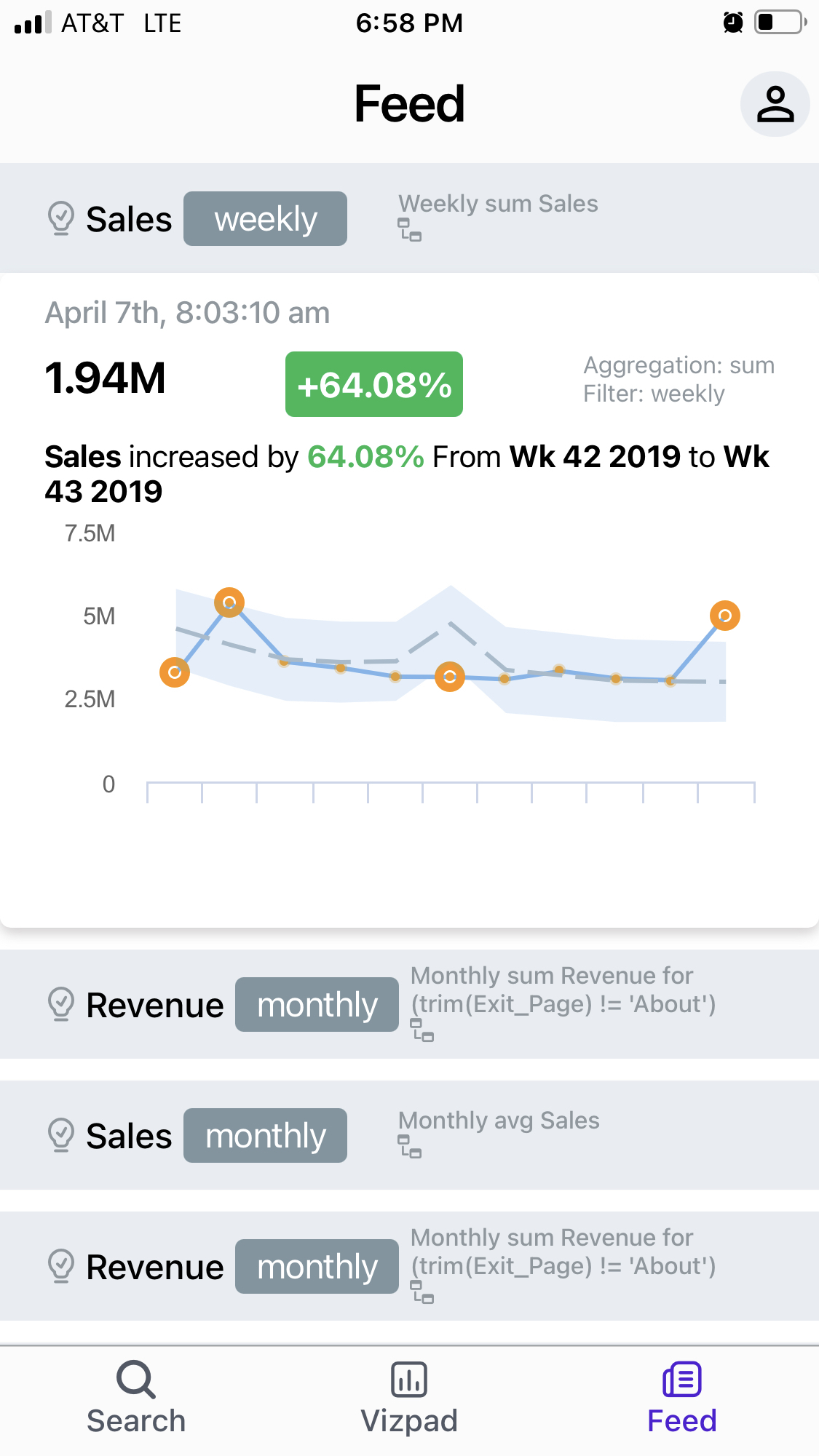
In Tinace 3.7, we have updated the Tinace Mobile iOS and Android native apps. We have added two new exciting features for search and feeds. This will enable users to perform a search against their Tinace instance while on the move. Additionally, users will have access to the latest Feeds of the KPIs of interest directly into the mobile app. With the Tinace Mobile app, users can get explore and access their business insights on the GO.
Search in Tinace App:
Feed in Tinace App:
Data
Display Name for Business Layer across all Tinace
In Tinace 3.7 we complete the integration of Display Names across the entire Tinace application. The Display Names is a concept that allows business users to add business names on top of the variables in the datasets and Business Views. This is the preferred method of changing the names for variables (as opposed to renaming columns) as it assures that there is no disruption in terms of refreshing the data in Tinace.
Display Names now have been integrated in the following areas of the application: Discover, Predict, Prepare Data and Business Views. For more detail please review the Display Names article.
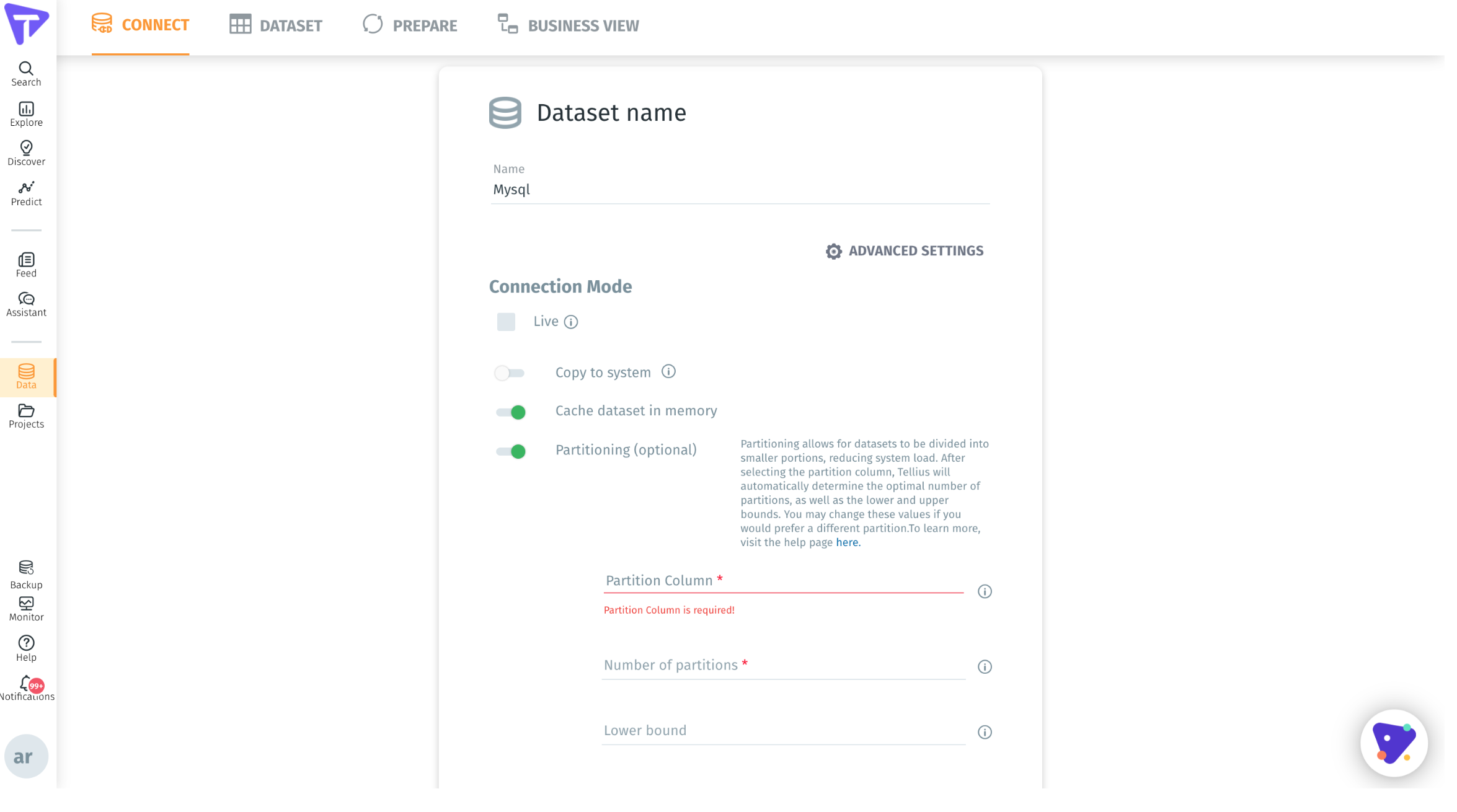
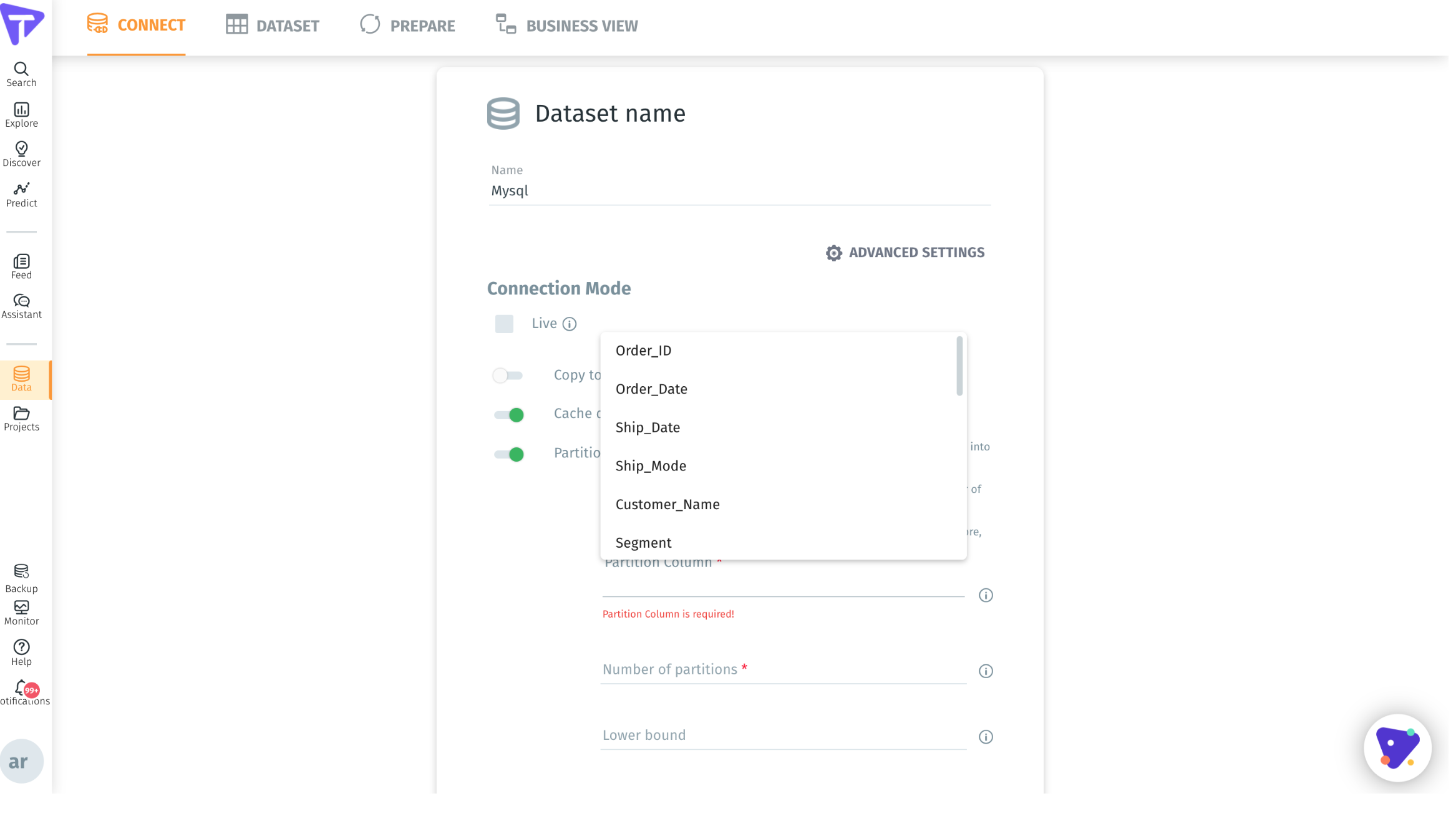
Auto Partition Discovery for JDBC Sources
In Tinace 3.7, the auto-partition discovery was added for JDBC Sources as an option that is turned on by default. This helps speed up and scale the way data is loaded into the application. Tinace has added automated calculations and suggestions to guide the user through the partition process. Once datasource is configured, the following steps are followed:
- User selects the Partition column for a drop down
- Tinace will load a subset of data, analyze data and recommend the partitions to user along with the logic of Partitioning and an explanation of how to provide a partition column
- Tinace will automatically partition for datasources like MySQL, Oracle, MSSQL when data is imported from JDBC sources.
SQL scripting support across multiple datasets
One of the exciting features in Tinace 3.7 is related to the flexibility added to support SQL scripting using multiple SQL tables as input and one SQL table as output. In addition to writing code from scratch, this feature is tremendously valuable for data engineers who have already existing code they can just move and run into Tinace with minimum edits. The scripting feature in Prepare Data allows users to engage in the following steps:
- Select one of the Input tables and then select Scripting from the view tab
- Select all the Input Tables, Name the Output Table and Create the Script
- Insert the Script, Run Validation and Create the Dataset
- View the Output table, go Back and edit the script
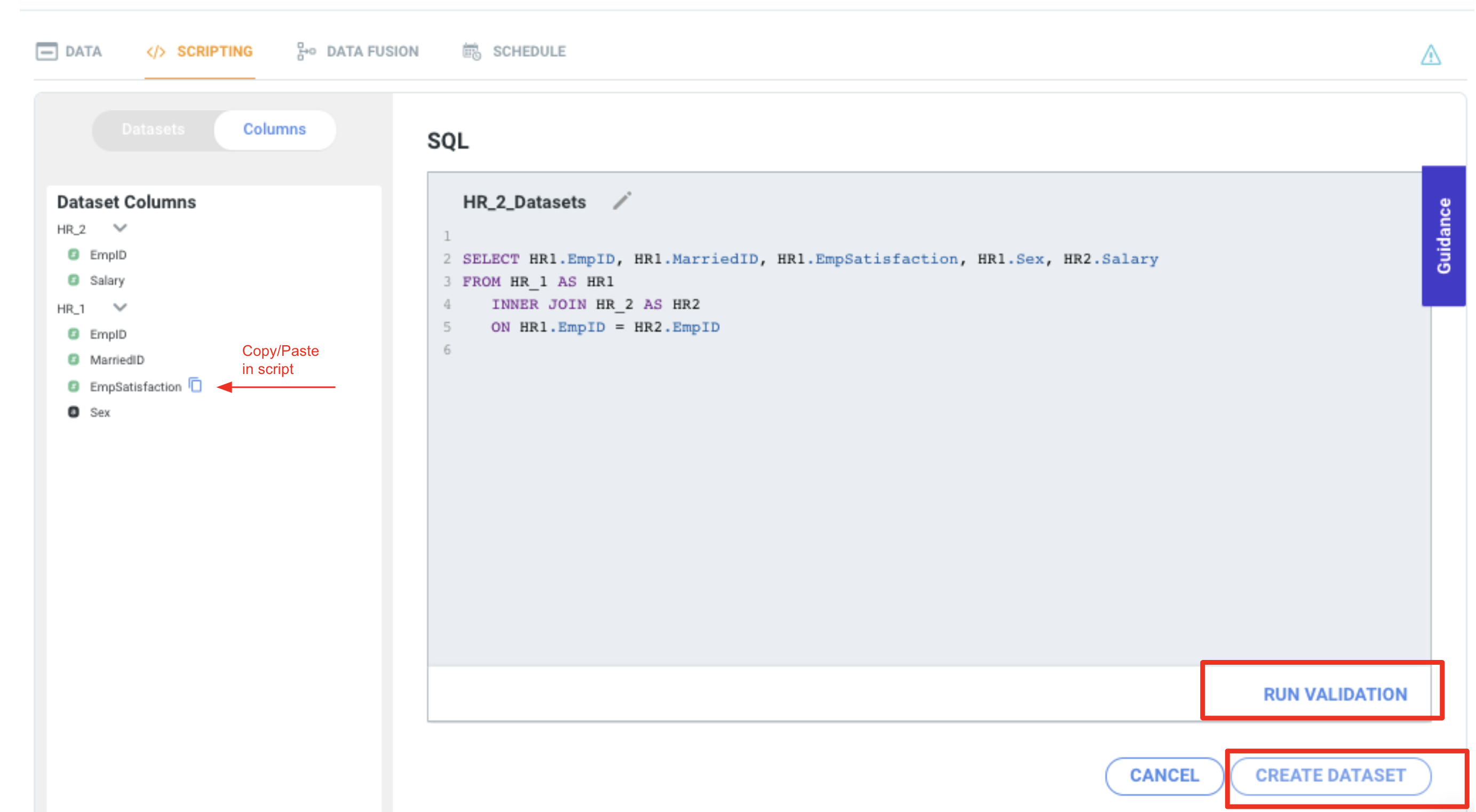
For more information please see details in Multiple Datasets Scripting article.
Search
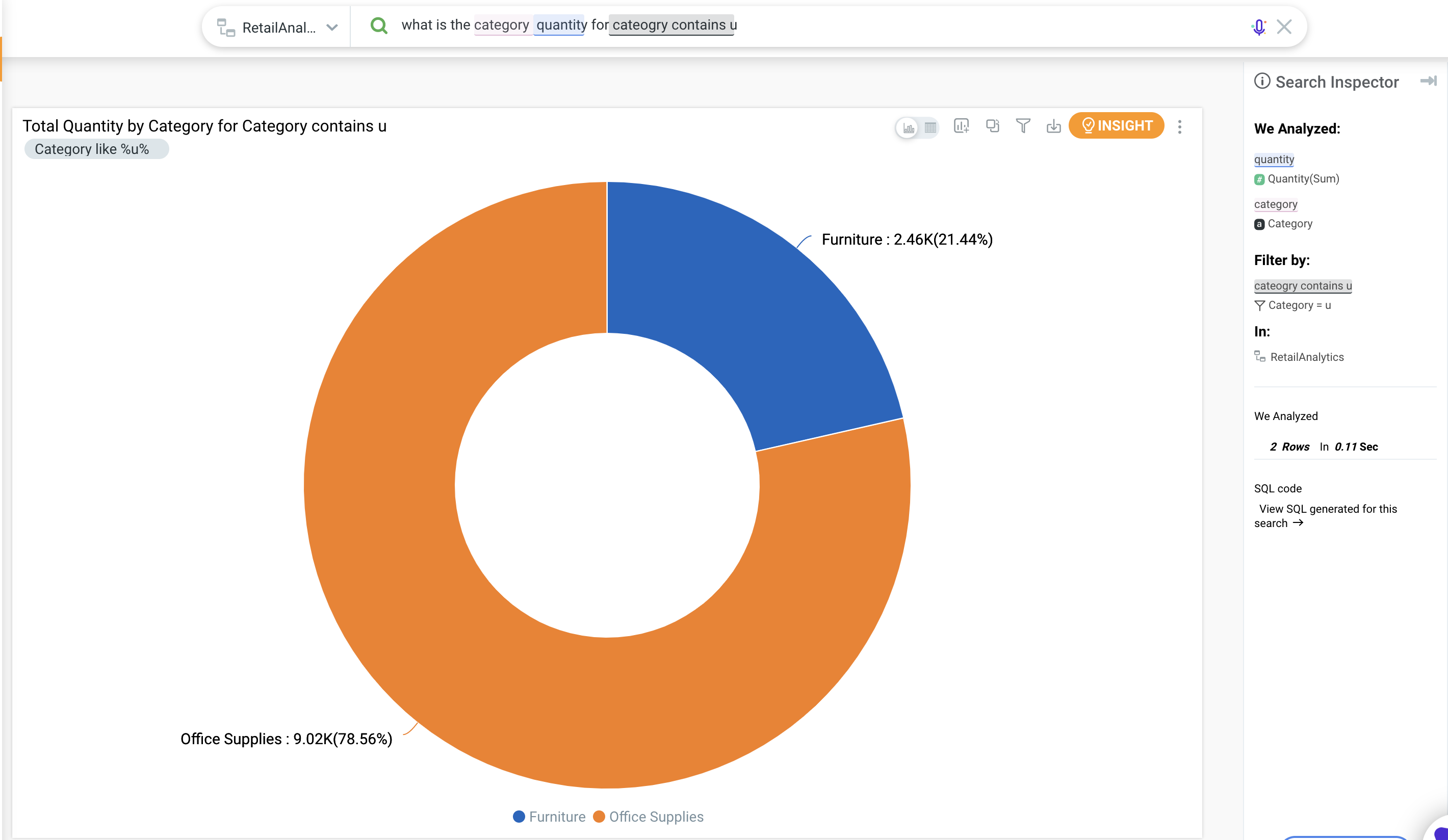
Comparison using "Contains" Operator
In Tinace 3.7, the search experience is enhanced from using the "=" operator to being able to use "contains" operator. This is particularly valuable when users are interested in querying dimension values like names of products (example: Movie Title contains Avengers).
Keyword free typing in Search queries
In Tinace 3.7, the user can now select a highlighted Entity in a previous search query and freely delete it or edit it with a basic type function without needed the drop down of suggestions. This is valuable if the users know exactly what the value they are interested in querying.